
Studie der Universität Augsburg zeigt, welche Informationen Anwendern helfen, die Qualität selbstlernender Algorithmen zu beurteilen
Selbstlernende Computerprogramme können heute enorm viel: das Wetter vorhersagen, Tumoren in Röntgenbildern entdecken, besser Schach spielen als jeder Mensch. Wie die Algorithmen ihre Schlüsse ziehen, wissen oft aber nicht einmal diejenigen, die sie programmiert haben. Forschende der Universität Augsburg und des Israel Institute of Technology (Technion) haben nun zwei Ansätze verglichen, diese „Blackbox“ etwas aufzuhellen. Die Studie zeigt, welche Informationen Anwendern helfen, die Qualität künstlich-intelligenter Verfahren zu beurteilen. Sie ist in der Zeitschrift Artificial Intelligence erschienen, einer der international renommiertesten Fachzeitschriften in der KI-Forschung.
Bei der Schach-WM in Dubai brachte der Norweger Magnus Carlsen kürzlich ein Bauernopfer, das viele Beobachter überraschte – auch, weil sein Zug augenscheinlich noch nie bei einer großen Partie gespielt worden war. Wenn Computer gegeneinander antreten, taucht er allerdings hin und wieder auf. Von Carlsen ist bekannt, dass er sein Spiel auch nach Erkenntnissen aus diesen Schlagabtäuschen der Maschinen ausrichtet. In einem Interview hat er den Schach-Algorithmus AlphaZero einmal als sein Idol bezeichnet.
AlphaZero ist ein selbstlernendes Programm, das sich in Millionen Duellen gegen sich selbst eine enorme Spielstärke angeeignet hat. Warum es sich in welchen Situationen wie entscheidet, ist aber selbst für Experten kaum ersichtlich. Das ist ein generelles Problem künstlich-intelligenter (abgekürzt: KI) Verfahren – wie sie zu ihren Schlussfolgerungen kommen, wissen sogar ihre Programmierer meist nicht. Ihr Verhalten ist eine Blackbox, und je größer die Aufgaben, die wir den Programmen anvertrauen, desto mehr wird das zum Problem: Wer will schon einer Maschine in bei einer Entscheidung von Leben und Tod blind vertrauen? Und wie lässt sich beurteilen, welcher von mehreren Algorithmen für eine Aufgabe am besten geeignet ist?
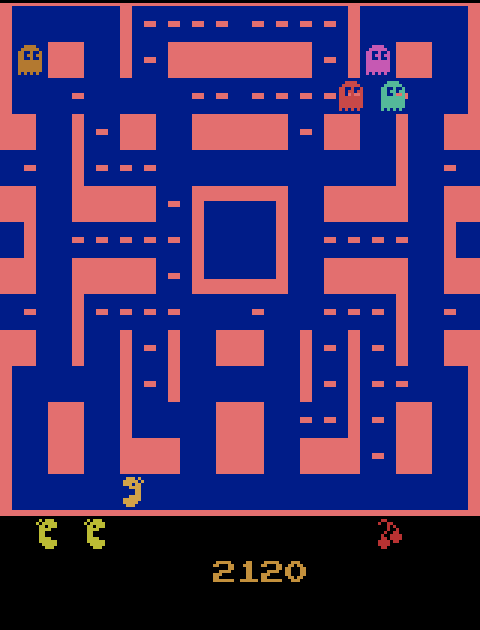
Ein wichtiges Anliegen der KI-Forschung ist es daher momentan, Licht in diese Blackbox zu bringen. Allerdings ist diese Aufgabe alles andere als trivial und beschäftigt die Wissenschaft schon seit vielen Jahren. Die neue Studie bringt die Forschung nun einen großen Schritt nach vorne. Tobias Huber, Katharina Weitz und Elisabeth André von der Universität Augsburg haben sich dazu mit der Forscherin Ofra Amir vom Israel Institute of Technology (Technion) zusammengetan. Das Problem, auf das sie ihr selbstlernendes Verfahren trainierten, war ebenfalls ein Spiel – allerdings nicht Schach, sondern Pac-Man.
Kekse fressen für die Forschung
Pac-Man ist ein japanisches Computerspiel, das 1980 seinen Siegeszug um die Welt antrat. „Es ist für eine KI eines der schwierigsten Arcade-Spiele“, erklärt Tobias Huber, der bei Prof. André am Lehrstuhl für Menschzentrierte Künstliche Intelligenz promoviert. Die Spielfigur muss Kekse in einem Labyrinth fressen und wird dabei von Geistern verfolgt. Für jeden Keks bekommt sie Punkte; wird sie erwischt, stirbt sie. Ähnlich wie Schach eignet sich das Spiel daher ausgezeichnet für eine besondere Kategorie von KI-Algorithmen, nämlich solche, die durch Verstärkung lernen.
„Wir lassen unser Programm Tausende Male hintereinander Pac-Man spielen“, sagt Huber. „Je besser ihre Strategie ist, desto mehr Punkte erreichen sie. Basierend auf seinen Vorerfahrungen lernt der Algorithmus so mit der Zeit, wie er sich in welcher Situation verhalten sollte.“ Doch wie kann ein Beobachter beurteilen, auf welchen Kriterien das Verhalten der KI basiert und wie gut ihre Entscheidungen sind?
Um das zu beurteilen, haben die Forschenden ein einfaches Experiment ersonnen. Zunächst trainierten sie den Computer auf das Spiel Pac-Man, modifizierten dabei aber insgeheim die Regeln, nach denen die Punkte vergeben wurden. In einem Fall verlor die Spielfigur beispielsweise keine Punkte, wenn sie starb. Der so trainierte Algorithmus (die Forschenden sprechen auch von einem „Agenten“) ließ sich daher in seinen Entscheidungen von etwaigen Geistern in der Nähe nicht beeindrucken. Für einen zweiten Agenten veränderten sie den Wert der Kekse; ein dritter spielte dagegen nach den normalen Regeln.
„Wir haben nun Testpersonen gebeten, die drei Agenten zu beurteilen“, erläutert Huber. „Dabei haben sie sich aber nicht etwa mehrere komplette Spiele ansehen dürfen, sondern bekamen nur kurze Ausschnitte zu sehen.“ Die Versuchspersonen sollten auf dieser Basis angeben, welchen der Agenten sie am ehesten in einem Pac-Man-Spiel für sich antreten lassen würden. Außerdem sollten sie die Strategie aller drei KI-Verfahren kurz in eigenen Worten beschreiben. „Wir wollten so herausfinden, ob die Versuchspersonen verstanden hatten, warum der Algorithmus bestimmte Aktionen ausführt“, sagt der Informatiker.
Zusammenfassung der „dramatischsten“ Spielszenen hilft am meisten
Die Teilnehmerinnen und Teilnehmer wurden dazu in vier Gruppen eingeteilt. Jede durfte sich fünf dreisekündige Ausschnitte aus den Spielen der drei Agenten anschauen. In der ersten Gruppe waren diese Kurzclips zufällig ausgewählt worden. Für die zweite Gruppe wurde in die Zufalls-Kurzfilmchen zusätzlich eine Art „Aufmerksamkeits-Landkarte“ eingeblendet. Sie zeigte, auf welche Einflüsse in seiner Umgebung der Agent in diesem Moment besonders achtete.
Die dritte Gruppe bekam dagegen die „dramatischsten“ Spielszenen zu sehen – das sind solche, in denen die Entscheidung des Agenten eine besonders große Tragweite hatte (also etwa zum Tod der Spielfigur oder einem besonders hohen Punktgewinn führen konnten). In der KI-Forschung spricht man auch von einer „Strategie-Zusammenfassung“. Bei der vierten Gruppe wurde diese Zusammenfassung zusätzlich um die Aufmerksamkeits-Landkarte ergänzt.
Das Ergebnis des Experiments fiel deutlich aus: „Versuchspersonenen, die die Zusammenfassung sahen, entwickelten dadurch am ehesten ein Gefühl für die Strategie des jeweiligen Agenten“, erklärt Huber. „Die Aufmerksamkeits-Karten halfen ihnen dagegen deutlich weniger. Auch in Kombination mit der Zusammenfassung entfalteten sie nur einen geringen Zusatznutzen.“ Es sei kognitiv sehr fordernd, sich die Spielausschnitte anzusehen und gleichzeitig auf die Informationen aus den Aufmerksamkeits-Karten zu achten. „Wir nehmen an, dass ihr Beitrag bei einer besseren Aufbereitung der Information größer wäre.“
Die Forschenden wollen nun untersuchen, wie man die Aufmerksamkeits-Karten so optimieren könnte, dass sie zusammen mit der Strategie-Zusammenfassung die Entscheidungen eines KI-Agenten noch besser nachvollziehbar machen.
Publikation:
Tobias Huber, Katharina Weitz, Elisabeth André, Ofra Amir: Local and global explanations of agent behavior: Integrating strategy summaries with saliency maps. Artificial Intelligence, Volume 301, 2021, https://doi.org/10.1016/j.artint.2021.103571.
(Pressemitteilung für die Universität Augsburg)